Forward框架的逆袭:解析Forward+渲染
AMD在7900系列显卡发布的时候同时推出了Leo demo,并说明它不是用近年流行的Deferred框架渲染完成,而是用到了一种叫Forward+的框架。这个框架不需要Deferred的大带宽要求,却仍能实时渲染上千光源。EG2012上有篇新paper叫做Forward+: Bringing Deferred Lighting to the Next Level,讲述的就是这个方法。但目前作者还没有放出该论文的全文,这里我只能通过只言片语和AMD的文档来解析这个神奇的Forward+。
Tiled-based Deferred Shading
在进入正题之前,我们先回顾一下Intel在SIGGRAPH Courses 2010里提到的Tiled-based Deferred Shading。它的算法框架是:
生成G-Buffer,这一步和传统deferred shading一样。
把G-Buffer划分成许多16×16的tile,每个tile根据depth得到bounding box。
对于每个tile,把它的bounding box和light求交,得到对这个tile有贡献的light序列。
对于G-Buffer的每个pixel,用它所在tile的light序列累加计算shading。
在原先的deferred框架下,每个light需要画一个light volume,以决定它会影响到哪些pixel(也就是light culling)。而用tiled based的方法,只需要一个pass就可以对所有的光源进行求交。如果用了AMD在Mecha demo中用到的OIT方法,还可以做一个per-tile linked list,直接把light序列存在链表里。
Forward+ Rendering
有了Tiled-based Deferred Shading的基础,理解Forward+就变得简单多了。Forward+ Rendering和Tiled-based Deferred Shading的关系就好比原先的Forward Shading和Deferred Shading,所以我们可以照猫画虎一次:
Z-prepass,很多forward shading都会用这个作为优化,而在forward+中,这个变成了必然步骤。
把Z-Buffer划分成许多16×16的tile,每个tile根据depth得到bounding box。
对于每个tile,把它的bounding box和light求交,得到对这个tile有贡献的light序列。
对于每个物体,在PS中用该pixel所在tile的light序列累加计算shading。
从这里可以看出,前两步与Tiled-based deferred shading大同小异,但只需要Z-Buffer,而不需要很消耗带宽的G-Buffer(G-Buffer最小也要32bit color + 32bit depth)。第三步是完全一样的。第四部由于用了forward,可以有forward的各种好处:
复杂材质
支持硬件AA(虽然我一直认为硬件AA多算了很多东西,是一种巨大的浪费)
带宽利用率高
支持透明物体
由于light已经在步骤3中cache了,所以也可以不像传统的forward那样,把材质和光源搅在一起。加上shader中动态分支的能力,不难实现类似deferred那样的巨量光源支持。由于带宽省了很多,Forward+的速度能比Deferred快。在原paper里的性能比较足以说明这个问题。
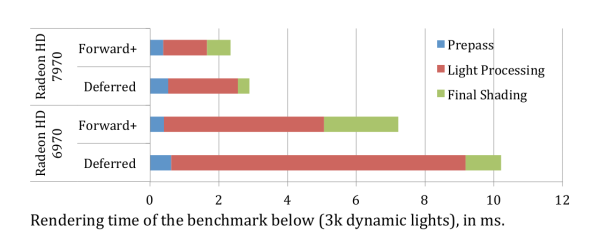
另一个有趣的地方是透明物体的渲染。虽然我在KlayGE中用Deep G-Buffer的方法解决了纯Deferred下透明物体的渲染。正如很多读者指出的,这么做所带来的带宽翻倍在很大程度上拖慢了整个系统。在Forward+中,第一步生成Z-prepass的时候,可以采用双Z-Buffer的办法,一个放不透明物体的Z,另一个放透明物体的Z。在第二步计算tile bounding box的时候,不管透不透明都放在一起计算一个总的bounding box。后面步骤不变,就能原生支持透明物体。
由于有了Z-Buffer,其他原先对Deferred有利的效果,比如GI、SSR,都可以直接应用。SSAO、SSVO之类的方法,如果需要考虑pixel normal,就需要适当的修改才能应用上。
在AMD的demo中,步骤2和3是用compute shader实现的。而在Tiled-based Forward Rendering这篇blog中,他完全用PS实现了per-tile linked list,但仍然需要D3D11的UAV特性。所以Forward+还没法再D3D11之前的硬件上实现。
总结
所谓三十年河东三十年河西,作为Forward框架的新发展,Forward+给我们提供了一个新思路。这样的竞争性发展总比所有资源都投到一方、忽视另一方要好。
从贡献程度来看,最有突破性的其实不是Forward部分,其实是Tiled-based。Forward+只能算作Tiled-based Deferred Shading的“Forward化”。顺便说一下,很多移动平台的GPU在硬件上支持Tiled-based Rendering(TBR),也是利用它来最大化计算相关性和带宽利用率。不支持TBR的Tegra就吃亏许多了。
Categories: Garfield's Diary